04-MySQL索引
1. 思考
2. 解决办法
3. 索引是什么
4. 索引目的
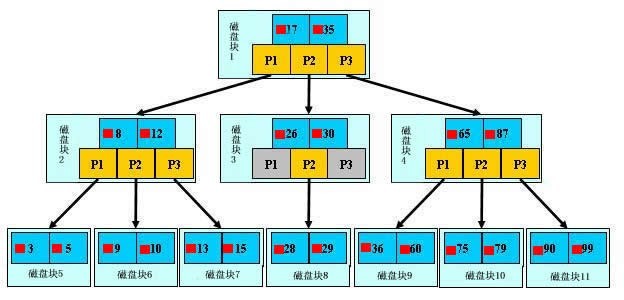
5. 索引原理
数据库也是一样,但显然要复杂许多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、
模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,
能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,
201到300分成第三段……这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。
6. 索引的使用
7.索引demo
8.注意:
9. mysql 索引
Last updated